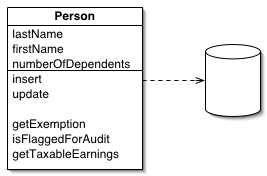
Das Active Record Pattern ist ein Designmuster, das häufig in der Softwareentwicklung verwendet wird, um die Verwaltung von Datenbankobjekten zu vereinfachen. Es stellt sicher, dass ein Objekt gleichzeitig die Datenstruktur und die Logik für den Zugriff auf diese Daten in einer relationalen Datenbank enthält. In diesem Artikel erklären wir das Active Record Pattern, zeigen ein Beispiel in C++ und Python und diskutieren seine Vor- und Nachteile.
Was ist das Active Record Pattern?
Das Pattern kombiniert die Datenstruktur eines Objekts mit den Methoden zum Speichern, Laden, Aktualisieren und Löschen der Daten aus der Datenbank. Ein Objekt, das dieses Muster implementiert, enthält sowohl die Daten selbst als auch die Logik für die Interaktion mit einer Datenquelle. Die Struktur des Objekts entspricht in der Regel einer Zeile einer Tabelle in einer relationalen Datenbank.
Funktionsweise des Pattern
In diesem Pattern ist jedes Objekt in der Anwendung eng mit einer Datenbanktabelle verbunden. Jedes Objekt repräsentiert eine einzelne Datenzeile. Die Methoden dieses Objekts kümmern sich um die Interaktion mit der Datenbank (z.B. Speichern, Aktualisieren und Löschen von Datensätzen). Dadurch wird die Geschäftslogik direkt in die Objekte integriert.
Die wichtigsten Aufgaben des Patterns sind:
- Speichern von Daten: Das Objekt enthält eine Methode, um sich selbst in der Datenbank zu speichern.
- Laden von Daten: Eine Methode lädt die Daten des Objekts aus der Datenbank.
- Aktualisieren von Daten: Wenn ein Objekt verändert wird, kann es mit einer Methode die Änderungen in der Datenbank aktualisieren.
- Löschen von Daten: Das Objekt kann sich selbst aus der Datenbank löschen.
Beispiel in C++
Angenommen, wir haben eine einfache Datenbanktabelle für Benutzer, die eine id, einen Name und eine Email enthält. Das Active Record Pattern könnte wie folgt in C++ implementiert werden.
1. Benutzerklasse
Zuerst definieren wir eine einfache Benutzerklasse, die das Active Record Pattern implementiert:
#include <iostream>
#include <string>
#include <unordered_map>
class User {
public:
User(int id, const std::string& name, const std::string& email)
: id(id), name(name), email(email) {}
int getId() const { return id; }
std::string getName() const { return name; }
std::string getEmail() const { return email; }
// Speichern des Objekts in der "Datenbank" (in diesem Fall ein HashMap)
void save() {
database[id] = *this;
std::cout << "Benutzer gespeichert: " << name << std::endl;
}
// Laden des Objekts aus der "Datenbank"
static User load(int id) {
return database.at(id); // Rückgabe des Benutzers aus der Map
}
// Aktualisieren des Objekts in der "Datenbank"
void update() {
database[id] = *this;
std::cout << "Benutzer aktualisiert: " << name << std::endl;
}
// Löschen des Objekts aus der "Datenbank"
void remove() {
database.erase(id);
std::cout << "Benutzer gelöscht: " << name << std::endl;
}
private:
int id;
std::string name;
std::string email;
static std::unordered_map<int, User> database; // Simulierte Datenbank
};
// Definition der statischen Datenbank
std::unordered_map<int, User> User::database;
2. Anwendung der Benutzerklasse
Nun verwenden wir die Benutzerklasse, um Daten zu speichern, zu laden, zu aktualisieren und zu löschen:
int main() {
// Benutzer erstellen und speichern
User user1(1, "Max Mustermann", "max@beispiel.com");
user1.save();
// Benutzer laden
User loadedUser = User::load(1);
std::cout << "Geladener Benutzer: " << loadedUser.getName() << std::endl;
// Benutzer aktualisieren
user1 = User(1, "Max Mustermann", "maxneu@beispiel.com");
user1.update();
// Benutzer löschen
user1.remove();
return 0;
}
In diesem Beispiel wird die Benutzerklasse als Active Record implementiert. Die Daten (Benutzername und E-Mail) werden direkt im Objekt gespeichert, und die Methoden save(), load(), update() und remove() ermöglichen den direkten Zugriff auf die „Datenbank“, die in diesem Fall durch eine einfache unordered_map simuliert wird.
Beispiel in Python
Das Active Record Pattern ist ein Entwurfsmuster, bei dem Objekte die Logik für das Speichern und Abrufen von Daten direkt verwalten. In Python können wir dieses Muster umsetzen, indem wir eine Klasse erstellen, die sowohl die Daten als auch die Methoden zum Speichern und Laden der Daten aus einer Datenbank enthält.
Ein einfaches Beispiel für das Active Record Pattern in Python könnte wie folgt aussehen:
- Datenbank-Verbindung (simuliert durch SQLite)
- Model-Klasse, die sowohl Daten speichert als auch Methoden für CRUD-Operationen enthält.
Hier ist ein Beispiel:
import sqlite3
class ActiveRecord:
# Verbindung zur SQLite-Datenbank
def __init__(self, db_name):
self.db_name = db_name
def _get_connection(self):
return sqlite3.connect(self.db_name)
class User(ActiveRecord):
def __init__(self, db_name, name=None, email=None, user_id=None):
super().__init__(db_name)
self.user_id = user_id
self.name = name
self.email = email
def save(self):
conn = self._get_connection()
cursor = conn.cursor()
if self.user_id: # Update, falls es bereits einen Benutzer gibt
cursor.execute("UPDATE users SET name = ?, email = ? WHERE id = ?",
(self.name, self.email, self.user_id))
else: # Neuer Benutzer, also Insert
cursor.execute("INSERT INTO users (name, email) VALUES (?, ?)",
(self.name, self.email))
self.user_id = cursor.lastrowid # Die ID des neuen Benutzers
conn.commit()
conn.close()
@classmethod
def find_by_id(cls, db_name, user_id):
conn = sqlite3.connect(db_name)
cursor = conn.cursor()
cursor.execute("SELECT id, name, email FROM users WHERE id = ?", (user_id,))
row = cursor.fetchone()
conn.close()
if row:
return cls(db_name, name=row[1], email=row[2], user_id=row[0])
return None
@classmethod
def all(cls, db_name):
conn = sqlite3.connect(db_name)
cursor = conn.cursor()
cursor.execute("SELECT id, name, email FROM users")
rows = cursor.fetchall()
conn.close()
return [cls(db_name, name=row[1], email=row[2], user_id=row[0]) for row in rows]
# SQLite-Datenbank initialisieren und Tabelle erstellen (falls noch nicht vorhanden)
def create_tables():
conn = sqlite3.connect('test.db')
cursor = conn.cursor()
cursor.execute('''
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
email TEXT NOT NULL
)
''')
conn.commit()
conn.close()
# Verwendung des Active Record Patterns
create_tables()
# Benutzer anlegen und speichern
user1 = User('test.db', 'Max Mustermann', 'max@example.com')
user1.save()
# Alle Benutzer abrufen
users = User.all('test.db')
for user in users:
print(f'ID: {user.user_id}, Name: {user.name}, Email: {user.email}')
# Einen Benutzer nach ID suchen
user_found = User.find_by_id('test.db', 1)
if user_found:
print(f'Gefundener Benutzer: ID={user_found.user_id}, Name={user_found.name}, Email={user_found.email}')
Erklärung des Codes:
- ActiveRecord-Klasse: Diese Basisklasse kümmert sich um die Verbindung zur Datenbank und stellt eine Methode bereit, um eine Verbindung zu öffnen.
- User-Klasse: Diese Klasse ist eine konkrete Implementierung des Active Record Patterns. Sie enthält:
- Attribute für Benutzer (
name,email,user_id). - Die Methode
save(), um einen Benutzer in der Datenbank zu speichern oder zu aktualisieren. - Die Klassenmethoden
find_by_id()undall(), um Benutzer aus der Datenbank abzurufen.
- Attribute für Benutzer (
- Datenbank: Wir verwenden SQLite, um eine einfache Datenbank zu simulieren, in der Benutzer gespeichert werden.
- CRUD-Operationen (CRUD = Create, Read, Update, Delete):
- Create: Die Methode
save()fügt einen neuen Benutzer hinzu oder aktualisiert einen bestehenden Benutzer. - Read: Die Methode
find_by_id()sucht einen Benutzer nach seiner ID, undall()gibt alle Benutzer zurück.
- Create: Die Methode
- Datenbankinitialisierung: Wir stellen sicher, dass die Datenbanktabelle
usersexistiert, bevor wir Operationen durchführen.
Dieses Beispiel zeigt, wie das Active Record Pattern verwendet werden kann, um sowohl die Daten als auch die Logik für das Speichern und Abrufen der Daten in einer Klasse zu kapseln.
Vorteile des Active Record Patterns
- Einfachheit: Das Active Record Pattern ist einfach zu implementieren und zu verstehen. Es erfordert keine komplexen Abstraktionen und eignet sich gut für einfache Anwendungen mit minimalen Datenbankoperationen.
- Geringe Entwicklungszeit: Da sowohl die Datenstruktur als auch die Logik für den Zugriff auf die Daten zusammen in einem Objekt verwaltet werden, wird die Entwicklungszeit oft reduziert.
- Wiederverwendbarkeit: Jedes Active Record-Objekt ist in sich geschlossen und kann in anderen Teilen der Anwendung wiederverwendet werden.
- Kohäsion: Das Pattern fördert die Kohäsion von Code, indem es Daten und Geschäftslogik im gleichen Objekt zusammenführt. Dies macht das System leichter zu pflegen.
Nachteile des Active Record Patterns
- Mangelnde Flexibilität: Das Active Record Pattern kann in komplexeren Systemen, die viele Geschäftslogiken und Datenmanipulationen erfordern, unpraktisch werden. Es kann schwierig sein, bei größeren und komplexeren Anwendungen zusätzliche Logik hinzuzufügen, ohne dass der Code überladen wird.
- Schwierig zu testen: Da die Logik direkt im Datenobjekt integriert ist, kann das Testen von Geschäftslogik schwieriger werden. Dies könnte zu einer schlechteren Testbarkeit führen.
- Verkoppelte Daten und Logik: Das Active Record Pattern bindet die Daten direkt an die Logik zur Datenmanipulation. Diese enge Kopplung kann es schwieriger machen, Änderungen am Datenmodell oder an der Datenbankstruktur vorzunehmen.
- Schwierigkeiten bei komplexen Abfragen: In Anwendungen, die komplexe Abfragen oder Join-Operationen erfordern, kann das Active Record Pattern ineffizient oder schwerfällig sein. Die Trennung von Geschäftslogik und Datenzugriffslogik ist in solchen Szenarien oft vorteilhafter.
Wann sollte man das Pattern einsetzen und wann nicht?
Das Active Record Pattern eignet sich besonders in den folgenden Szenarien:
1. Einfache Anwendungen oder kleine Projekte:
- Das Active Record Pattern ist besonders nützlich, wenn du eine einfache Datenbankanwendung entwickelst, bei der die Entitäten und die Datenbankoperationen nicht zu komplex sind.
- Bei kleinen Projekten mit nur wenigen Entitäten und grundlegenden CRUD-Operationen kann das Active Record Pattern schnell und effektiv implementiert werden, ohne zu viel Boilerplate-Code zu benötigen.
2. Schnelle Entwicklung:
- Wenn du in kurzer Zeit eine Anwendung entwickeln musst und keine komplexen Geschäftslogiken erforderlich sind, bietet das Active Record Pattern eine schnelle Möglichkeit, Modelle und Datenbankoperationen zu verbinden.
- Es spart Entwicklungszeit, da du keine separate Datenzugriffsschicht (wie ein Repository oder Data Mapper) erstellen musst.
3. Einfaches, CRUD-orientiertes System:
- Wenn deine Anwendung hauptsächlich CRUD-Operationen ausführt (Erstellen, Lesen, Aktualisieren und Löschen von Datensätzen) und keine komplexen Abfragen oder Transaktionen erforderlich sind, ist das Active Record Pattern eine gute Wahl.
- In einem einfachen System, das nicht viele Beziehungen zwischen Entitäten hat und keine komplexen Geschäftslogiken benötigt, ist es völlig ausreichend.
4. Wiederverwendbarkeit und einfache Wartung:
- In einem kleinen Team oder für individuelle Projekte, bei denen du die Datenbankoperationen eng mit den Entitäten verknüpfen möchtest, hilft das Active Record Pattern, das Projekt übersichtlich zu halten.
- Jede Entität hat ihre eigenen Methoden für die Datenmanipulation, was die Wartung der Datenbankoperationen erleichtert, ohne eine separate Schicht für die Datenbankinteraktionen zu erstellen.
5. Lesbarkeit und Klarheit:
- Durch das Verknüpfen von Daten und Methoden in der gleichen Klasse bleibt der Code klar und gut lesbar. Es ist einfach zu verstehen, wie das Modell und seine Methoden zusammenarbeiten.
- Das Active Record Pattern kann den Code vereinfachen, weil die Daten und die Logik zum Speichern/Laden der Daten in einer einzigen Klasse zusammengefasst sind.
Wann sollte man es nicht verwenden?
- Komplexe Geschäftslogik oder große Anwendungen:
- Wenn deine Anwendung eine komplexe Geschäftslogik oder viele Entitäten mit komplexen Beziehungen (z. B. viele zu viele oder viele zu eins) enthält, kann das Active Record Pattern zu unübersichtlichem und schwer wartbarem Code führen.
- In solchen Fällen ist es besser, ein anderes Muster wie Data Mapper oder Repository Pattern zu verwenden, das eine klare Trennung zwischen Geschäftslogik und Datenzugriffslogik bietet.
- Tests und Flexibilität:
- Das Active Record Pattern kann schwieriger zu testen sein, besonders bei komplexen Operationen, weil die Datenzugriffslogik und die Entitäten eng miteinander verknüpft sind. Bei größeren, testgetriebenen Projekten kann es besser sein, die Datenbanklogik von den Entitäten zu trennen.
- Wenn du viele unterschiedliche Datenquellen oder eine ausgeklügelte Persistenzschicht benötigst (z. B. NoSQL-Datenbanken, unterschiedliche Datenbanktypen oder APIs), ist das Active Record Pattern möglicherweise nicht flexibel genug.
- Hohe Performanceanforderungen:
- Wenn du eine Anwendung mit sehr hohen Performanceanforderungen hast, bei der du die Datenbankabfragen sehr präzise kontrollieren musst (z. B. bei großen Datenmengen oder hochkomplexen Abfragen), ist es besser, ein Muster zu wählen, das die Datenbankabfragen und Geschäftslogik klar trennt, wie z. B. das Repository Pattern.
- Datenbankmigrationen und -abstraktionen:
- Bei Anwendungen, die eine komplexe Datenbankstruktur haben oder eine fortlaufende Migration der Datenbank benötigen (z. B. bei großen Systemen oder bei Systemen mit ständig wechselnden Anforderungen), könnte das Active Record Pattern schwerfällig werden, da es oft schwierig ist, Schemaänderungen ohne zusätzliche Werkzeuge oder manuelle Anpassungen durchzuführen.
Das Active Record Pattern eignet sich hervorragend für kleine bis mittelgroße Projekte, bei denen die Geschäftslogik einfach und die Datenbankoperationen überschaubar sind. Wenn du eine einfache, gut lesbare Lösung für CRUD-Operationen benötigst, ist es eine schnelle und effektive Wahl. Bei komplexeren Anforderungen oder großen Anwendungen sollte jedoch ein anderes Designmuster in Betracht gezogen werden, um eine bessere Trennung von Anliegen und Flexibilität zu gewährleisten.
Fazit
Das Active Record Pattern ist ein nützliches Designmuster für Anwendungen, die eine einfache und schnelle Datenverwaltung benötigen. Besonders für kleinere Projekte oder einfache CRUD-Anwendungen bietet es viele Vorteile, wie etwa eine einfache Implementierung und schnelle Entwicklung. Allerdings kann es bei komplexeren Anwendungen und umfangreichen Datenoperationen an seine Grenzen stoßen. Es ist wichtig, die Vor- und Nachteile dieses Musters abzuwägen, bevor man sich für dessen Einsatz entscheidet.
Active Record Pattern
Gibt es Bibliotheken oder Frameworks für Active Record Pattern in C++?
Im Embedded-Bereich sind Active Record Frameworks selten. In C++ können jedoch kleine Libraries oder eigene Mini-ORMs verwendet werden. In größeren Embedded-Systemen mit Linux können Frameworks wie SQLite mit einem C++ Wrapper sinnvoll eingesetzt werden, um das Active Record Pattern umzusetzen.
Ist das Active Record Pattern auch für Embedded-Programmierung in C/C++ sinnvoll?
Das Active Record Pattern kann auch in Embedded-Systemen Anwendung finden – insbesondere wenn lokale Datenhaltung (z. B. in EEPROM oder einer Datei) erforderlich ist. Obwohl Embedded-Systeme oft keine klassische SQL-Datenbank nutzen, lässt sich das Pattern anpassen, um strukturiert mit persistenten Daten umzugehen, etwa in Form von Binärdateien oder Flashspeicher. Für C/C++-Entwickler bedeutet dies mehr Klarheit beim […]
Wann sollte man auf das Active Record Pattern im Embedded-Bereich verzichten?
Verzichten sollte man auf das Active Record Pattern, wenn: Memory Footprint kritisch ist (z. B. < 2KB RAM). Hohe Echtzeit-Anforderungen (z.B. SIL3)bestehen (Pattern kann zusätzlichen Overhead verursachen). Maximale Trennung von Logik und Datenhaltung gewünscht ist. In solchen Fällen sind funktionale oder modulare Ansätze oft effizienter.
Was ist das Active Record Pattern in einfachen Worten?
Das Active Record Pattern ist ein Software-Entwurfsmuster, bei dem ein Objekt einer Klasse direkt mit einer Datenbanktabelle verknüpft ist. Jedes Objekt repräsentiert eine Zeile der Tabelle und enthält sowohl die Daten als auch Methoden zum Speichern, Aktualisieren, Löschen und Laden aus der Datenbank. Das Active Record Pattern wird häufig in ORMs wie Ruby on Rails […]
Welche Alternativen gibt es zum Active Record Pattern in der Embedded-Entwicklung?
Alternativen zum Active Record Pattern in C/C++ Embedded-Projekten sind u. a.: Data Mapper Pattern: Trennung von Datenobjekten und Persistenzlogik. Repository Pattern: Zentrale Verwaltung aller Datenzugriffe. Service Layer Pattern: Isolierung von Geschäftslogik und Datenzugriff. Diese Patterns ermöglichen bessere Testbarkeit und Flexibilität – erfordern aber zusätzlichen Abstraktionsaufwand.
Welche Nachteile hat das Active Record Pattern im Embedded-Kontext?
Das Active Record Pattern bringt auch Herausforderungen mit sich: Speicherverbrauch: Mehr RAM- und Flashbedarf durch zusätzliche Methoden. Kopplung: Starke Kopplung von Daten und Logik, was in sehr modularen Systemen problematisch sein kann. Testbarkeit: Testen der Datenlogik kann schwieriger sein, wenn nicht sauber abstrahiert wird. Für Systeme mit extrem limitierten Ressourcen (z. B. 8-Bit-Mikrocontroller) kann ein einfacheres […]
Welche Vorteile bietet das Active Record Pattern für Embedded-Systeme?
Strukturierte Datenhaltung: Klare Abbildung von Datenobjekten auf Speicherbereiche. Wartbarkeit: Vereinfachte Wartung durch zentrale Methoden für Datenoperationen. Konsistenz: Einheitliche Schnittstelle für CRUD-Operationen. Erweiterbarkeit: Leicht um weitere Felder und Operationen erweiterbar. Gerade bei Embedded-Anwendungen, die persistenten Speicher benötigen (z. B. Logger, Konfigurationen), bietet das Active Record Pattern eine robuste Struktur.
Wie beeinflusst das Active Record Pattern die Codequalität in Embedded-Systemen?
Das Active Record Pattern fördert eine bessere Strukturierung und Klarheit im Datenhandling. Die Kapselung von Speicher- und Geschäftslogik in einem Objekt erhöht die Lesbarkeit und reduziert Fehlerquellen. Bei sorgfältiger Implementierung führt dies zu wartbarem, erweiterbarem Code – auch in ressourcenbegrenzten Embedded-Systemen.
Wie kann das Active Record Pattern in C oder C++ implementiert werden?
In C++ lässt sich das Active Record Pattern relativ elegant umsetzen, indem man eine Klasse erstellt, die sowohl Daten (z. B. Konfigurationsparameter) als auch Methoden wie save(), load(), update() oder delete() enthält. Der Speicher kann dabei EEPROM, Flash oder eine einfache Datei sein. Beispiel: class ConfigRecord { public: int id; std::string name; void save(); void load(int […]
Wie kombiniert man das Active Record Pattern mit EEPROM- oder Flash-Speicher?
In C oder C++ kann man das Active Record Pattern so anpassen, dass save() und load() direkt auf EEPROM- oder Flash-Speicher zugreifen. Das funktioniert über Low-Level-APIs oder HAL-Funktionen (Hardware Abstraction Layer). Dabei wird typischerweise der Speicherblock einer festen Adresse zugeordnet. void ConfigRecord::save() { eeprom_write(address, reinterpret_cast<uint8_t*>(this), sizeof(ConfigRecord)); } Wichtig ist, dass Datenstrukturen korrekt gepackt sind (#pragma […]
Zurück zur Design-Pattern-Übersicht: Liste der Design-Pattern